To scientists, machine learning is a relatively old technology. The last decade has seen considerable progress, both as a result of new techniques – back propagation & deep learning, and the transformers algorithm – and massive investment of private sector resources, especially computing power. The result has been the striking and hugely publicised success of large language models.
But this rapid progress poses a paradox – for all the technical advances over the last decade, the impact on productivity growth has been undetectable. The productivity stagnation that has been such a feature of the last decade and a half continues, with all the deleterious effects that produces in flat-lining living standards and challenging public finances. The situation is reminiscent of an earlier, 1987, comment by the economist Robert Solow: “You can see the computer age everywhere but in the productivity statistics.”
There are two possible resolutions of this new Solow paradox – one optimistic, one pessimistic. The pessimist’s view is that, in terms of innovation, the low-hanging fruit has already been taken. In this perspective – most famously stated by Robert Gordon – today’s innovations are actually less economically significant than innovations of previous eras. Compared to electricity, Fordist manufacturing systems, mass personal mobility, antibiotics, and telecoms, to give just a few examples, even artificial intelligence is only of second order significance.
To add further to the pessimism, there is a growing sense that the process of innovation itself is suffering from diminishing returns – in the words of a famous recent paper: “Are ideas getting harder to find?”.
The optimistic view, by contrast, is that the productivity gains will come, but they will take time. History tells us that economies need time to adapt to new general purpose technologies – infrastructures & business models need to be adapted, and the skills to use them need to be spread through the working population. This was the experience with the introduction of electricity to industrial processes – factories had been configured around the need to transmit mechanical power from central steam engines through elaborate systems of belts and pulleys to the individual machines, so it took time to introduce systems where each machine had its own electric motor, and the period of adaptation might even involve a temporary reduction in productivity. Hence, one might expect a new technology to follow a J-shaped curve.
Whether one is an optimist or a pessimist, there are a number of common research questions that the rise of artificial intelligence raises:
- Are we measuring productivity right? How do we measure value in a world of fast moving technologies?
- How do firms of different sizes adapt to new technologies like AI?
- How important – and how rate-limiting – is the development of new business models in reaping the benefits of AI?
- How do we drive productivity improvements in the public sector?
- What will be the role of AI in health and social care?
- How do national economies make system-wide transitions? When economies need to make simultaneous transitions – for example net zero and digitalisation – how do they interact?
- What institutions are needed to support the faster and wider diffusion of new technologies like AI, & the development of the skills needed to implement them?
- Given the UK’s economic imbalances, how can regional innovation systems be developed to increase absorptive capacity for new technologies like AI?
A finer-grained analysis of the origins of our productivity slowdown actually deepens the new Solow paradox. It turns out that the productivity slowdown has been most marked in the most tech-intensive sectors. In the UK, the most careful decomposition similarly finds that it’s the sectors normally thought of as most tech intensive that have contributed to the slowdown – transport equipment (i.e., automobiles and aerospace), pharmaceuticals, computer software and telecoms.
It’s worth looking in more detail at the case of pharmaceuticals to see how the promise of AI might play out. The decline in productivity of the pharmaceutical industry follows several decades in which, globally, the productivity of R&D – expressed as the number of new drugs brought to market per $billion of R&D – has been falling exponentially.
There’s no clearer signal of the promise of AI in the life sciences than the effective solution of one of the most important fundamental problems in biology – the protein folding problem – by Deepmind’s programme AlphaFold. Many proteins fold into a unique three dimensional structure, whose precise details determine its function – for example in catalysing chemical reactions. This three-dimensional structure is determined by the (one-dimensional) sequence of different amino acids along the protein chain. Given the sequence, can one predict the structure? This problem had resisted theoretical solution for decades, but AlphaFold, using deep learning to establish the correlations between sequence and many experimentally determined structures, can now predict unknown structures from sequence data with great accuracy and reliability.
Given this success in an important problem from biology, it’s natural to ask whether AI can be used to speed up the process of developing new drugs – and not surprising that this has prompted a rush of money from venture capitalists. One of the most high profile start-ups in the UK pursuing this is BenevolentAI, floated on the Amsterdam Euronext market in 2021 with €1.5 billion valuation.
Earlier this year, it was reported that BenevolentAI was laying off 180 staff after one of its drug candidates failed in phase 2 clinical trials. Its share price has plunged, and its market cap now stands at €90 million. I’ve no reason to think that BenevolentAI is anything but a well run company employing many excellent scientists, and I hope it recovers from these setbacks. But what lessons can be learnt from this disappointment? Given that AlphaFold was so successful, why has it been harder than expected to use AI to boost R&D productivity in the pharma industry?
Two factors made the success of AlphaFold possible. Firstly, the problem it was trying to solve was very well defined – given a certain linear sequence of amino acids, what is the three dimensional structure of the folded protein? Secondly, it had a huge corpus of well-curated public domain data to work on, in the form of experimentally determined protein structures, generated through decades of work in academia using x-ray diffraction and other techniques.
What’s been the problem in pharma? AI has been valuable in generating new drug candidates – for example, by identifying molecules that will fit into particular parts of a target protein molecule. But, according to pharma analyst Jack Scannell [1], it isn’t identifying candidate molecules that is the rate limiting step in drug development. Instead, the problem is the lack of screening techniques and disease models that have good predictive power.
The lesson here, then, is that AI is very good at the solving the problems that it is well adapted for – well posed problems, where there exist big and well-curated datasets that span the problem space. Its contribution to overall productivity growth, though, will depend on whether those AI-susceptible parts of the overall problem are in fact the rate-limiting steps.
So how is the situation changed by the massive impact of large language models? This new technology – “generative pre-trained transformers” – consists of text prediction models based on establishing statistical relationships between the words found in a massively multi-parameter regression over a very large corpus of text [3]. This has, in effect, automated the production of plausible, though derivative and not wholly reliable, prose.
Naturally, sectors for which this is the stock-in-trade feel threatened by this development. What’s absolutely clear is that this technology has essentially solved the problem of machine translation; it also raises some fascinating fundamental issues about the deep structure of language.
What areas of economic life will be most affected by large language models? It’s already clear that these tools can significantly speed up writing computer code. Any sector in which it is necessary to generate boiler-plate prose, in marketing, routine legal services, and management consultancy is likely to be affected. Similarly, the assimilation of large documents will be assisted by the capabilities of LLMs to provide synopses of complex texts.
What does the future hold? There is a very interesting discussion to be had, at the intersection of technology, biology and eschatology, about the prospects for “artificial general intelligence”, but I’m not going to take that on here, so I will focus on the near term.
We can expect further improvements in large language models. There will undoubtedly be improvements in efficiencies as techniques are refined and the fundamental understanding of how they work is improved. We’ll see more specialised training sets, that might improve the (currently somewhat shaky) reliability of the outputs.
There is one issue that might prove limiting. The rapid improvement we’ve seen in the performance of large language models has been driven by exponential increases in the amount of computer resource used to train the models, with empirical scaling laws emerging to allow extrapolations. The cost of training these models is now measured in $100 millions – with associated energy consumption starting to be a significant contribution to global carbon emissions. So it’s important to understand the extent to which the cost of computer resources will be a limiting factor on the further development of this technology.
As I’ve discussed before, the exponential increases in computer power given to us by Moore’s law, and the corresponding decreases in cost, began to slow in the mid-2000’s. A recent comprehensive study of the cost of computing by Diane Coyle and Lucy Hampton puts this in context [2]. This is summarised in the figure below:
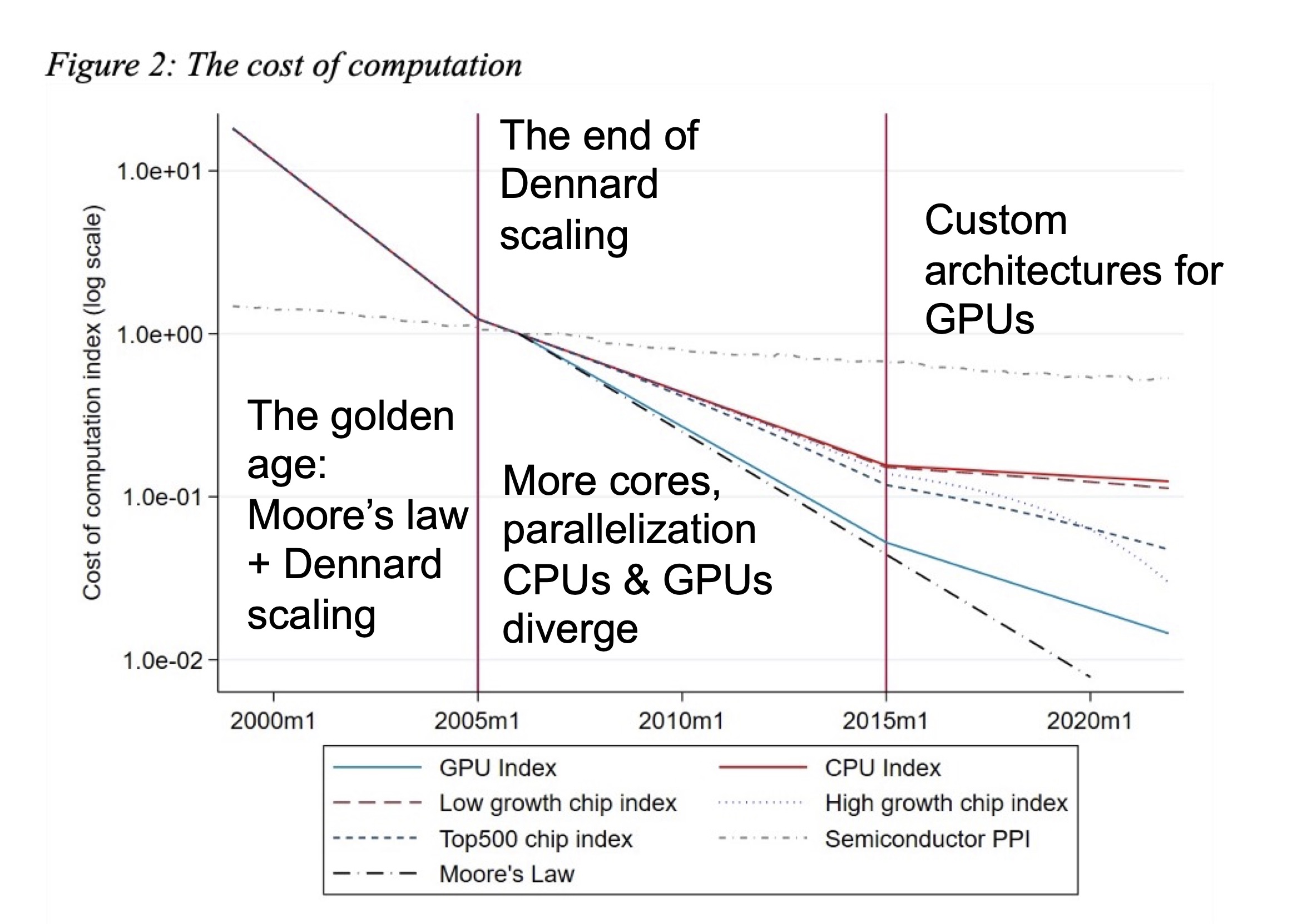
The cost of computing with time. The solid lines represent best fits to a very extensive data set collected by Diane Coyle and Lucy Hampton; the figure is taken from their paper [2]; the annotations are my own.
The highly specialised integrated circuits that are used in huge numbers to train LLMs – such as the H100 graphics processing units designed by NVIdia and manufactured by TSMC that are the mainstay of the AI industry – are in a regime where performance improvements come less from the increasing transistor densities that gave us the golden age of Moore’s law, and more from incremental improvements in task-specific architecture design, together with simply multiplying the number of units.
For more than two millennia, human cultures in both east and west have used capabilities in language as a signal for wider abilities. So it’s not surprising that large language models have seized the imagination. But it’s important not to mistake the map for the territory.
Language and text are hugely important for how we organise and collaborate to collectively achieve common goals, and for the way we preserve, transmit and build on the sum of human knowledge and culture. So we shouldn’t underestimate the power of tools which facilitate that. But equally, many of the constraints we face require direct engagement with the physical world – whether that is through the need to get the better understanding of biology that will allow us to develop new medicines more effectively, or the ability to generate abundant zero carbon energy. This is where those other areas of machine learning – pattern recognition, finding relationships within large data sets – may have a bigger contribution.
Fluency with the written word is an important skill in itself, so the improvements in productivity that will come from the new technology of large language models will arise in places where speed in generating and assimilating prose are the rate limiting step in the process of producing economic value. For machine learning and artificial intelligence more widely, the rate at which productivity growth will be boosted will depend, not just on developments in the technology itself, but on the rate at which other technologies and other business processes are adapted to take advantage of AI.
I don’t think we can expect large language models, or AI in general, to be a magic bullet to instantly solve our productivity malaise. It’s a powerful new technology, but as for all new technologies, we have to find the places in our economic system where they can add the most value, and the system itself will take time to adapt, to take advantage of the possibilities the new technologies offer.
These notes are based on an informal talk I gave on behalf of the Productivity Institute. It benefitted a lot from discussions with Bart van Ark. The opinions, though, are entirely my own and I wouldn’t necessarily expect him to agree with me.
[1] J.W. Scannell, Eroom’s Law and the decline in the productivity of biopharmaceutical R&D,
in Artificial Intelligence in Science Challenges, Opportunities and the Future of Research.
[2] Diane Coyle & Lucy Hampton, Twenty-first century progress in computing.
[3] For a semi-technical account of how large language models work, I found this piece by Stephen Wolfram very helpful: What is ChatGPT doing … and why does it work?